- ChatGPT Tutorial
- ChatGPT - Home
- ChatGPT - Fundamentals
- ChatGPT - Getting Started
- ChatGPT - How It Works
- ChatGPT - Prompts
- ChatGPT - Competitors
- ChatGPT - For Content Creation
- ChatGPT - For Marketing
- ChatGPT - For Job Seekers
- ChatGPT - For Code Writing
- ChatGPT - For SEO
- ChatGPT - Machine Learning
- ChatGPT - Generative AI
- ChatGPT - Build a Chatbot
- ChatGPT - Plugin
- ChatGPT Useful Resources
- ChatGPT - Quick Guide
- ChatGPT - Useful Resources
- ChatGPT - Discussion
How Does ChatGPT Work?
Artificial Intelligence (AI) has become an integral part of how we live, work, and interact with the world around us. Within AI, there are several verticals such as natural language processing (NLP), computer vision, machine learning, robotics, etc. Among them, NLP has emerged as a critical area of research and development. ChatGPT, developed by OpenAI, is one of the best examples of the advancements made in NLP.
Read this chapter to know how ChatGPT works, the rigorous training process it undergoes, and the mechanism behind its generation of responses.
What is GPT?
At the core of ChatGPT lies the powerful technology called GPT that stands for "Generative Pre-trained Transformer". It is a type of AI language model developed by OpenAI. GPT models are designed to understand and generate natural language text almost like how humans do.
The image given below summarizes the major points of GPT −
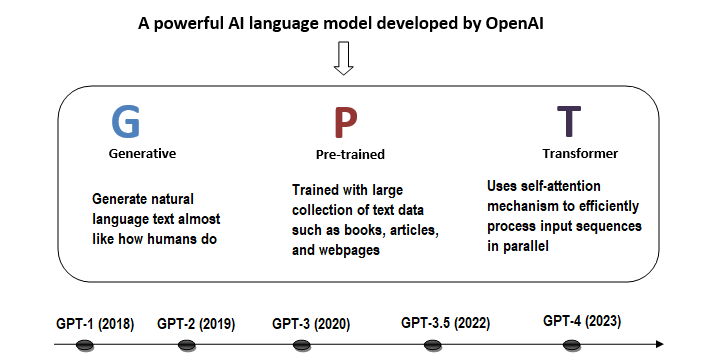
Components of GPT
Let’s break down each component of GPT −
Generative
Generative, in simple terms, refers to the model’s ability to generate new content like text, images, or music, based on the patterns it has learned from training data. In the context of GPT, it generates original text that sound like they were written by a human being.
Pre-trained
Pre-training involves training a model on a large dataset. In this phase, the model basically learns relationships withing the data. In case of GPT, the model is pretrained on vast amount of text from books, articles, websites, and more using unsupervised learning. This helps GPT to learn to predict the next word in a sequence.
Transformer
The transformer is a deep learning architecture used in the GPT model. Transformer uses a mechanism called self-attention to weigh the importance of different words in a sequence. It enables GPT to understand the relationship between words and allow it to produce more human like outputs.
How ChatGPT Was Trained?
ChatGPT was trained using a variant of GPT architecture. Below are the stages involved in training ChatGPT −
Language Modelling
ChatGPT was pre-trained on a large collection of text data from the internet, such as books, articles, websites, and social media. This phase involves training the model to predict the next word in a sequence of text given all the preceding words in the sequence.
This pre-training step helps the model learn the statistical properties of natural language and develop a general understanding of human language.
Fine Tuning
After pre-training, ChatGPT was fine-tuned for conversational AI tasks. This phase involves further training the model on a smaller dataset having data such as dialogue transcripts or chat logs.
During fine-tuning, the model uses techniques such as transfer learning to learn generating contextually relevant responses to the user queries.
Iterative Improvement
During the training process, the model is evaluated on various metrics like response coherence, relevance, and fluency. Based on these evaluations, to improve the performance the training process may be iterated.
How Does ChatGPT Generate Responses?
ChatGPT’s response generation process uses components like neural network architecture, attention mechanism, and probabilistic modeling. With the help of these components, ChatGPT can generate contextually relevant and quick responses to the users.
Let’s understand the steps involved in ChatGPT’s response generation process −
Encoding
The response generation process of ChatGPT starts with encoding the input text into a numerical format so that the model can process it. This step converts the words or subwords into embeddings using which the model captures semantic information about the user input.
Language Understanding
The encoded input text is now fed into the pre-trained ChatGPT model that further process the text through multiple layers of transformer blocks. As discussed earlier, the transformer blocks use self-attention mechanism to weigh the importance of each token in relation to the others. This helps the model to contextually understand the input.
Probability Distribution
After preprocessing the input text, ChatGPT now generates a probability distribution over the vocabulary for the next word in the sequence. This probability distribution has each word being the next in sequence, given all the preceding words.
Sampling
Finally, ChatGPT uses this probability distribution to select the next word. This word is then added to the generated response. This response generation process continues until a predefined stopping condition is met or generates an end-of-sequence token.
Conclusion
In this chapter, we first explained the foundation of ChatGPT which is an AI language model called Generative Pre-trained Transformer (GPT).
We then explained the training process of ChatGPT. Language modelling, fine tuning, and iterative improvements are the stages involved in its training process.
We also discussed briefly how ChatGPT generates contextually relevant and quick responses. It involves encoding, language understanding, probability distribution and sampling, which we discussed in detail.
ChatGPT, through its integration of the GPT architecture, rigorous training process, and advanced response generation mechanisms, represents a significant advancement in AIdriven conversational agents.
To Continue Learning Please Login